Step to build tf-lite micro speach example for nxp_k66f
1. Clone tensorflow code
$>git clone https://github.com/tensorflow/tensorflow.git
2. Install mbed-cli
$>sudo apt install python3 python3-pip git mercurial
$>python3 -m pip install mbed-cli
3. Install ARM cross compile toolchain.(In this project I use GNU Arm Embedded Toolchain)
https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-rm/downloads
4. Configure mbed cli
$>mbed config -G GCC_ARM_PATH=/YOUR_COMPILER_INSTALL_PATH/gcc-arm-none-eabi-9-2020-q2-update/bin
5. Generate mbed project for nxp_k66f
$>cd tensorflow
$>make -f tensorflow/lite/micro/tools/make/Makefile TARGET=mbed TAGS="nxp_k66f" generate_micro_speech_mbed_project
6. Create mbed project
$>cd tensorflow/lite/micro/tools/make/gen/mbed_cortex-m4/prj/micro_speech/mbed
$>mbed new .
7. Configure porject usin C++ 11
python -c 'import fileinput, glob;
for filename in glob.glob("mbed-os/tools/profiles/*.json"):
for line in fileinput.input(filename, inplace=True):
print line.replace("\"-std=gnu++14\"","\"-std=c++11\", \"-fpermissive\"")'
8 Connect the USB cable to nxp_k66f
9. Compile and flash project, after flash complete reset the board.
mbed compile --target K66F --toolchain GCC_ARM --profile release --flash
10. Connect to nxp_k66f serial port with baudrate 14400.
11. Saying Yes and NO and will print repsonse word in serial port, since nxp_k66f has onboard microphone you can direct speak to it and see the result in terminal.
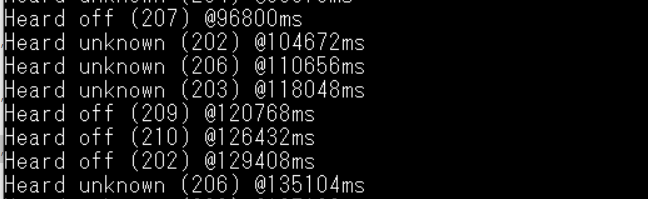
12. Test result
I want using this sample code to build a IOT switch that can control with speach, So in next article I will try to retrain model with 'ON' and 'OFF' key word and try to deploy to nxp_k66f
Ref
Mbed
https://os.mbed.com/docs/mbed-os/v6.9/build-tools/install-and-set-up.html
Tensorflow lite
https://github.com/tensorflow/tensorflow/tree/114b8ef31ac66155ec9b0590bc7115125f7fe61e/tensorflow/lite/micro/examples/micro_speech#deploy-to-nxp-frdm-k66f
NXP_K66F user guide
https://www.nxp.com/docs/en/user-guide/FRDMK66FUG.pdf